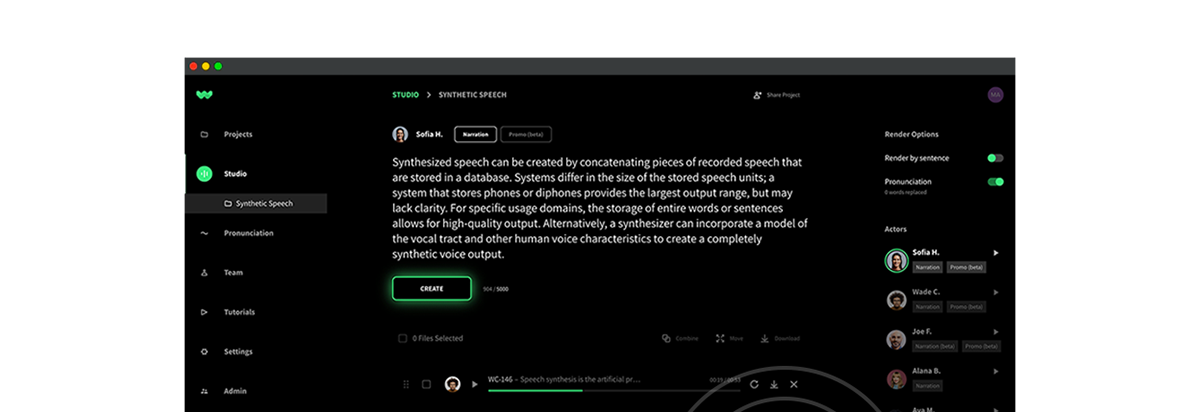
When you’ve watched a video online, have you ever considered whether the voiceover was actually a human voice? Sounds sci-fi, but these days, many companies rely on an emerging technology called text-to-speech to bring their voiceovers, scripts, and learning content to life. In this article, we discuss what text-to-speech is, how it compares to actual human voiceovers, and how you can generate shockingly life-like natural voices with an online text-to-speech platform.
What is text-to-speech?
Text-to-speech is a form of predictive technology that pronounces written words aloud, turning text into speech. Many companies use text-to-speech for learning and development content, training videos, and audio versions of transcripts, such as podcasts. For example, a healthcare company could use text-to-speech to voiceover their field training materials about preventing cardiac arrest in order to train their workforce with the latest best practices.
In the past, there was only one option for recording a voiceover: a human voice. Many companies used either in-house employees to record their content or outsourced voiceovers to recording studios. However, technology has flipped the switch on another form of voiceover: AI voices. Before you start envisioning robots and cyborgs, press pause—you likely can’t tell the difference between a human voiceover or a natural-sounding synthetic voice.
So, what is a natural voice exactly?
Natural voices are voices that sound human, whether from a person or synthetic form. Although, historically, companies relied on either human voiceover artists or employees for voiceovers, both routes can be unexpectedly inefficient and cost-prohibitive.
With recording studios, for example, not only does it take time to find the right voiceover artist, book time on their calendar, then wait to record, but recordings often require retakes, rewrites, and other minor adjustments that further slow down the process. Companies often have to coach voiceover artists on how to say specific terminology or company jargon and may have to re-record if not done properly. On average, 60 minutes with a voice actor or agency costs roughly $1,249, whereas the exact same 60 minutes costs just $11.76 via a synthetic text-to-speech platform.
Many companies opt for cost-savings by using in-house employees, but this too presents its challenges. Most employees aren’t trained voiceover artists, so it burdens them with hours of recording in addition to their regular responsibilities. And most offices aren’t the ideal recording environments nor set up to be recording studios, so every time an employee needs to record something, they must fabricate a room with the right acoustics, microphones, headphones, and technology… every time, for every retake or update. Then, because your average employee isn’t trained to speak to call sheet (i.e. with inflection, pace, and tone), the final voiceover is often inconsistent at best. This leads to substandard training materials that can reflect poorly on the company, despite all the time and effort involved. Once all is said and done (pun intended) the average cost to record voiceover in-house amounts to $900. Not exactly a bargain, given that synthetic text-to-speech costs roughly $12—or, at most, around $156 even if you factor in employee time.
The alternative to human voiceovers are synthetic voiceovers. But whereas the voiceovers of yore may have sounded somewhat robotic, with the power of today’s technology, synthetic text-to-speech sounds completely life-like. In fact, WellSaid Labs conducted a study in which participants rated human voiceovers and synthetic voiceovers equally life-like, as verified by a third-party firm.
How do you get text-to-speech voices to sound natural?
The power of natural-sounding text-to-speech is in the algorithm and the platform. While not all text-to-speech platforms sound completely natural-sounding, those like WellSaid Labs focus on a few patterns to make the voices sound surprisingly human. Then, they give you the power to edit, adapt and train the algorithm to produce a better product each and every time.
For example, whereas less sophisticated text-to-speech voices may pronounce words exactly the same every time, WellSaid Labs Avatars vary how they say words. Because the Avatars are algorithms learning from actual human voices, the Avatars add inflections, vary pace and fluctuate their tone. They can even weave in local variations, such as differences in the way people say aunt (ant vs. ah-nt) or caramel (car-mel vs. care-a-mel).
What’s more, you get to be in control of which natural-sounding text-to-speech voices you use. For example, depending on whether you’re recording that training about cardiac arrest or a hip new software, you may want completely different Avatars. Various tones, paces and pitches create a completely different level of credibility and understanding for your listeners.
The text-to-speech of the future
With all of these benefits, text-to-speech has never been a more natural-sounding, efficient and budget-supportive way to bring scripts, videos and learning and development materials to life.
To hear for yourself, check out WellSaid Labs sample text-to-speech voices.
Credits
Photo by Jakob Owens on Unsplash